
能登半島地震の死者データをエクセルで分析する
令和6年1月1日の能登半島地震から1年2か月以上が過ぎましたが、未だに死者の年齢や性別などについてデータが公表されていません(2025年3月21日現在)。震災で亡くなった方々の、年齢や性別、死因などは、今後の災害対応にとって極めて重要であることから、そのデータが未だに存在しないことはまことに残念なことです。
そこで、一部公表されている石川県のデータを活用して、いくつかの分析をします。最終成果は「死因」、「死者の住所地」、「年齢と性別」の3つです。
今回は、エクセルのCOUNTIF、COUNTIFS、そしてINDEXという3つの関数を学ぶ教材にもなっています。
【どのようなデータが公表されているか?】
現在、石川県からは同意が得られた方のみ、氏名や住所地、性別、年齢、死因が、公表された日付ごとに分かれて、漸次公表されています。⇒「お亡くなりになった方の氏名等」(石川県)
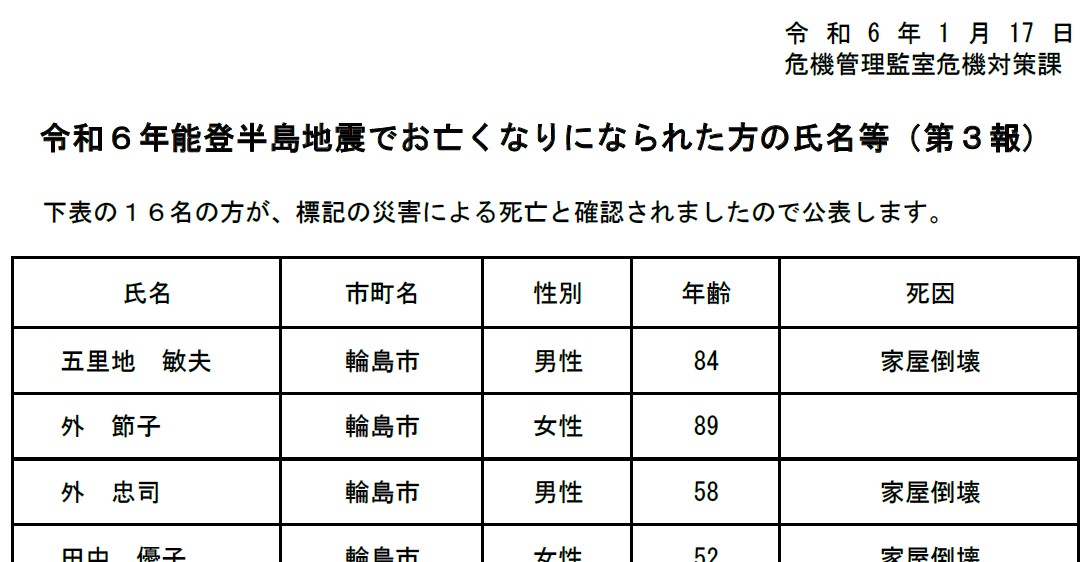
これは表形式になっているので、一見すると、そのままエクセルで使えそうですが、実は、これをコピペしてエクセルに貼り付けると、縦一列に並んでしまいます。そうすると、上記のうち、例えば「死因」だけ抽出するとかの1項目だけの集計ならVLOOKUP関数やCOUNTIF関数で集計できますが、2項目が連携した例えば年齢と性別の関係などは集計できません。一般的なpdfであればAltキーを押しながらコピーしたら縦列のコピーが可能ですが、この石川県の資料はどうもそれもできないものとなっていました。そこで以下の前処理を行います。
【縦横の表をエクセルで作成する】
<前処理>
まず、すべてのデータをコピペして、縦一列のデータを作ります。このとき、先ほど示した図のように、ところどころで死因の項目が抜けています。項目が抜けていると、縦横集計するとずれてくるので具合悪いです。そのためコピペした後で、抜けているところに「不明」と書き加えました。これですべてのデータが5つずつ順に縦に並ぶことができました。なお、このずらっと縦に並べたエクセルはここから入手できますので、これを使って以下の作業を自分でやってみてください。今回の作業の対象は、「直接死」に焦点を当てていますので、2月19日発表までのものを集計しています(それ以降の発表はすべて関連死です)。
<縦横にならべる>
5項目ごとに順に一列に690個並んだデータを横5列に配分するための作業をします。
縦に並んだデータを「Sheet1」に置きます。(上記作業を終えていたら、あるいは上記のエクセルを開いたら、すでにそうなっています)
別のシートを開きそこに縦横表を作ります。(下のシートの「+」マークを押すと新しいシートが追加されます)
新たにひらいたシートのA列1行目の桝に下記の関数を書きます。
=INDEX(Sheet1!A:A, (ROW()-1)*5+COLUMN())
続いてB列、C列、D列、E列の1行目にこれと同じ関数をコピペして貼り付けます。
以上の作業で、Sheet1の上から5つのデータが横に5つになって並んでいるはずです。
次に、1行目の5項目をクリックしながらなぞって選択し、1行目のEの右下にカーソルを持っていくとマークが+マークに変わりますので、それをクリックしたまま一気に下まで押し下げてください(オートフィル機能といいます)。
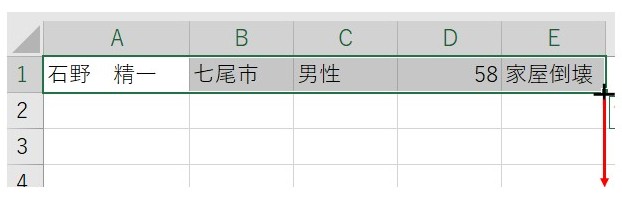
そうすると全部が5つずつにならべ替えられた、縦横の一覧表になります。(このブログの最後にINDEX関数の説明を加えておきますので、わからない人はそれを読んでください)
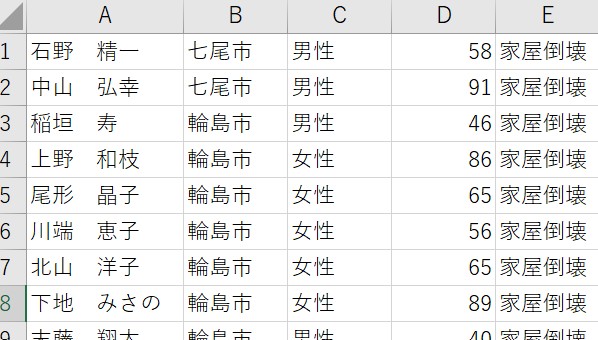
今回は直接死だけとしたいので、死因が不明の分は削除しましたので、全部で129人のデータとなりました。
これは石川県の死者数の約6割弱となっています。
【死因を集計】
以上でデータの準備ができました。
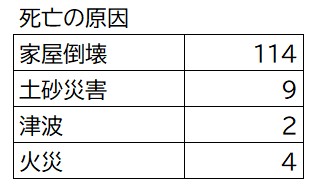
まず手始めに死因を集計して見ましょう。COUNTIFという関数を使います。
家屋倒壊で亡くなられた人の集計はE列の死因の中から集計するので、
=COUNTIF($E$1:$E$129,”家屋倒壊”)
という関数です。列と行の前にはそれぞれ$マークを加えて「絶対参照」としています。
残りの項目も上記の関数の”(死因項目)”の文字を入れ替えたらすぐに集計できます。
下表ができました。
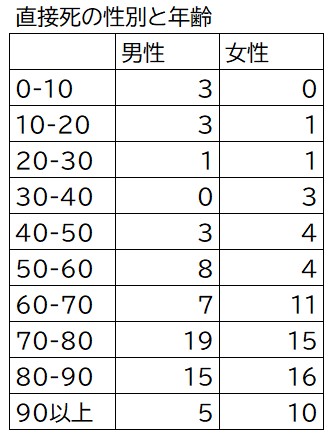
【死者の性別と年齢で集計】
今回の作業で使う関数はCOUNTIFSです。前項のCOUNTIFにSが付いているだけですが、これで複数の条件設定ができます。
この表ではC列に性別、D列に年齢となっていますので、
10歳までの男性は =COUNTIFS($D$1:$D$129,”<10“,$C$1:$C$129,”男性“)
という関数です。女性の場合は上記の”男性”を”女性”に変更します。
10-20歳の男性は、
=COUNTIFS($D$1:$D$129,”>=10“,$D$1:$D$129,”<20“,$C$1:$C$129,”男性“)
以下同様に数字と性別を入れ替えます。
最後の90歳以上、男性の関数は
=COUNTIFS($D$1:$D$129,”>=90“,$C$1:$C$129,”男性“)
このようにしてすべての関数が入ったら自動計算されます。
できた表は下記です。
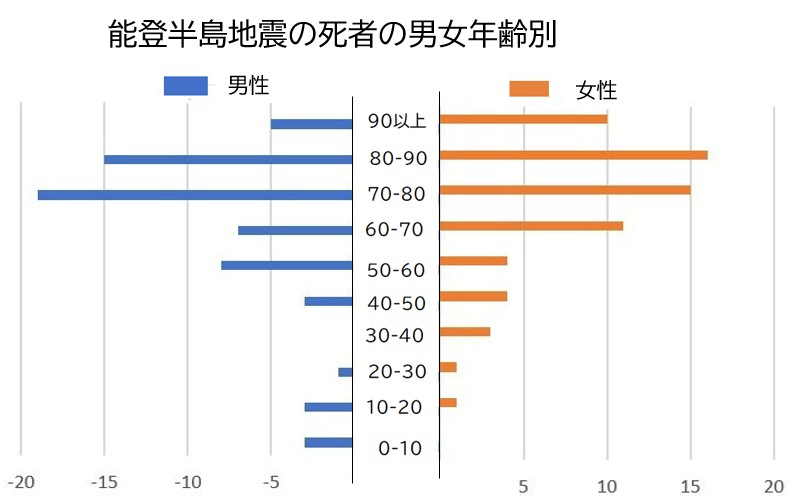
これをグラフにしたものも示しておきます。(画像ソフトで一部加工しています)
【住所地で集計】
亡くなられた方の住所地でも集計できます。
=COUNTIF($B$1:$B$129,”輪島市“)
同様に、珠洲市、穴水町・・等で集計します。下表ができました。
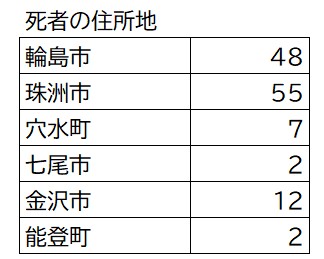
これで気が付くのは地震の被害が小さいはずの金沢市で死者が多いことです。住所登録地なので、金沢在住の方がなくなられたということでしょう。地震が1月1日で帰省していた方が多かったことに起因していると考えられます。年齢を見ると下表のようになっていて若い方がほとんどでした。
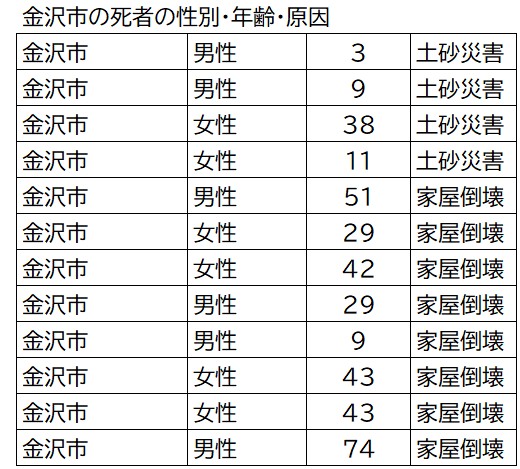
今回集計したように、大量のデータから特定の条件のものだけを表示したいことはよくありますね。金沢市在住分の集計をする関数の解説は次のINDEX関数の解説の後ろにつけています。
なお、Chat GPTにこの元データの石川県のリンクを見せてエクセルの表に作ってもらうこともできます。私がお願いしたときは最初は一部のデータしか変換しなかったのですが、繰り返し全部してほしいとお願いしたらやってくれました。(2025年4月24日追記)
※INDEX関数の解説
縦に1列のずらーっと並んだ5項目ずつのデータは以下の関数で5列の表示にできます。
=INDEX(Sheet1!A:A, (ROW()-1)*5+COLUMN())
与えられたINDEX関数の式=INDEX(Sheet1!A:A, (ROW()-1)*5+COLUMN())は、Sheet1シートのA列から特定のセルの値を取得するために使用されます。
この関数を横の4列にもコピーしたら項目ごとに展開されます。
数式の各部分を分解して、その動作を説明します。
INDEX(Sheet1!A:A, …):
Sheet1!A:Aは、Sheet1シートのA列全体を指定しています。つまり、この数式はSheet1シートのA列から値を取得します。
INDEX関数は、指定された範囲(ここではSheet1!A:A)から、指定された行番号と列番号に対応するセルの値を返します。
(ROW()-1)*5+COLUMN():
この部分が、INDEX関数における行番号を指定しています。
ROW():
ROW()関数は、数式が入力されているセルの行番号を返します。
COLUMN():
COLUMN()関数は、数式が入力されているセルの列番号を返します。
列番号なので、Aなら1、Bなら2、Cなら3、Dなら4・・・となっていきます。
(ROW()-1)*5+COLUMN():
この計算式は、数式が入力されているセルの行番号と列番号に基づいて、Sheet1!A:Aから値を取得する行番号を動的に計算します。
結果として、数式が入力されているセルの位置によって、参照するSheet1!A:Aの行が変化します。
数式の動作例を検証します
例えば、この数式がセルC1に入力されている場合:
ROW()は1を返し、COLUMN()はCは数字では3なので3を返します。
したがって、(ROW()-1)*5+COLUMN()は(1-1)*5+3=3となり、INDEX関数はSheet1!A:Aの3行目の値を返します。
例えば、この数式がセルC2に入力されている場合:
ROW()は2を返し、COLUMN()は、Cは3つ目なので3を返します。
したがって、(ROW()-1)*5+COLUMN()は(2-1)*5+3=8となり、INDEX関数はSheet1!A:Aの8行目の値を返します。
この検証でわかるようにC1とC2では式によって返す数字の差が5なのでSheet1のC1で選んだ項目から5つ飛んだ項目をC2に表示することがわかりますね。
このように、この数式は、数式が入力されているセルの位置に応じて、Sheet1!A:A(Sheet1のA列)から異なる行の値を順番に取得するために使用できます。なお、今回は5つの項目の繰り返しなので関数式の中の数字が「5」となっていますが、いくつづつの繰り返しのケースでもこの数字を変えれば使えます。
金沢市在住分の集計方法
大量のデータから特定の条件のものだけを表示したいことはよくあります。その関数を紹介します。私のPCは少し古いのでFILTER関数は使えないので、INDEX関数とAGGREGATE関数を使う方法(Excel 2010以降は使えます)で行ないました。INDEX関数とAGGREGATE関数を組み合わせることで、より柔軟な抽出が可能です。
=IFERROR(INDEX(A:A,AGGREGATE(15,6,ROW(A$1:A$138)/(B$1:B$138=”金沢市”),ROW(A1))),””)
この式では、A列から名前を抽出し、B列の「金沢市」と一致する行のデータを順に表示します。
(注)上式はデータ数が138なのでそうしていますが、データ数に応じて数字を変更してください
ROW(A$1:A$138)/(B$1:B$138=”金沢市”): B列が「金沢市」と一致する行番号の配列を生成します。
AGGREGATE(15,6,…,ROW(A1)): 生成された配列から、小さい順にk番目の値を返します。
INDEX(A:A,…): 返された行番号に基づいて、A列から対応する名前を抽出します。
IFERROR(…,””): エラーが発生した場合(該当データがない場合)に、空白を表示します。
性別はAをCに、年齢はDに、死因はEに変更して、同様の式をそれぞれの列に合わせて作成します。
このように抽出したい項目がある行を入れ替えたら、どんな項目に着目しても使えます。
例えば死因の「不明」のみを表示したい場合は、B$1:B$138=”金沢市” の部分を死因はE列なので、 E$1:E$138=”不明” と入れ替えた次式とすればよい。1行目を表示させたらオートフィルで下にドラッグ。
=IFERROR(INDEX(A:A,AGGREGATE(15,6,ROW(A$1:A$138)/(E$1:E$138=”不明”),ROW(A7))),””)
上の式は名前の列(すなわちA列)を表示なので、以下表示したい項目の列にアルファベットを替えればよい。
“能登半島地震の死者データをエクセルで分析する” に対して1件のコメントがあります。